
作者:林渝修
重點整理:
- Bunching 是一種樣本點聚集在特定數值的現象,而 Bunching Method 是藉由使用行政資料來找尋因果關係,並將行政資料的聚集與經濟模型結合以萃取模型參數的計量方法。
- Bunching Method 不僅能用來找出有利政策執行的模型參數,也能用來識別一些外在因素干擾及不理性行為的效果及大小。
- 任何計量研究都必須考慮國家、制度、環境等,以此才能給出可信的因果推論。
引言與 Bunching 初步介紹
報稅季節,辛苦一年的收入要上繳給國家,想到這點讓妳不想再工作了嗎?從政府的角度來看,當然不希望所得稅過高而導致大家都不工作,因此如何訂稅率以維持勞動供給就成為了重要的政策問題。稅收對於勞動供給的經濟理論在 20 世紀後期就已經發展相對成熟,但政策執行面對的問題則是,實證研究是否支持理論模型呢?進一步的問,學者如何用實證方法去測量模型參數,以利政府制定政策呢?Bunching Method 就是由 2009 年克拉克獎得主 Emmanuel Saez 在 2010 年的論文 Do Taxpayers Bunch at Kink Points? 中嘗試解答這些問題中所誕生的。
*Bunching 是一種現象,描述資料中樣本點聚集在某個特定的數值。而 Bunching Method 就是從這樣的聚集來萃取出模型參數的方法。*讓我們用一個例子,來看邊際稅率的調整,在經濟理論上會如何改變勞動供給。從中可以知道我們為何「預期」會有樣本點(這個情境下,樣本點就是納稅人)的聚集,以及我們可以從中了解到怎麼樣的資訊。
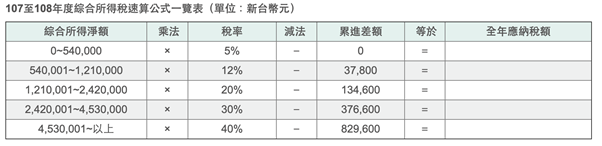
由圖一我們可以算一下年收入 54 萬和年收入 55 萬的人的稅後淨收入。
54 萬:540,000 x (1 - 0.05) = 513,000
55 萬:540,000 x (1 - 0.05) + 10,000 x (1 - 0.12) = 521,800
那麼讓我們假設,為了這多出的 8800 元你的每週工時必須拉長 30 分鐘,你會願意嗎?讓我們進一步假設在這個世界,人們雖然無法決定工資,卻可以自由選擇工時。邊際稅率調整讓年收入 55 萬的人相對於 5 % 稅率時少賺了 700 元,也許你會覺得,那還是有 8800 啊!但總會有那麼一群非常厭惡工作,少賺那 700 元就不願意多工作而寧願將年收入固定在 54 萬的人存在。因此,相比於稅率永遠都是 5 % 的假想世界裡,現實世界裡年收入 54 萬這個數值上應該會聚集(bunch)多一點的人。
上述的聚集其實描述了經濟學中「勞動供給彈性」的意涵,這是種衡量稅率改變導致行為改變的參數。如果人們的勞動供給隨著邊際稅率改變而有大幅的調整,那麼就能理解為勞動供給十分有彈性,這個數值就相對的會比較大,反之亦然。回到上面的例子,「理論上」我們如果把納稅人口收入資料完整地列出來,應該要在每一個邊際稅率調整的地方都看到這樣的聚集。但「真正的資料」是否呈現這樣的聚集呢?
觀察真正的資料是否有這樣的聚集以及聚集的幅度就是 Bunching Method 的精髓。
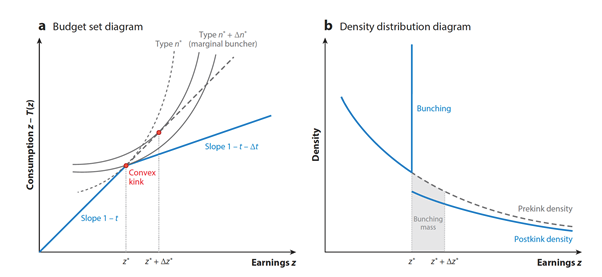
對於個體經濟有一點認識的人可以在圖二看無異曲線的分析。這裡要特別提及的假設是:收入(Earnings) =工時 × 薪資、且每個人的薪資是天生無法改變的。
為何用 Bunching?
你可能接下來會問:
- Bunching 不是只要觀察稅收資料就能看到了,有什麼好稀奇的?
- 觀察到之後又要怎麼跟經濟理論中的參數做連結?
想像一下我們隨機抽取 1000 個台灣納稅人口,那只有極低的機率會有足夠多的人位於每個累進區間旁,那麼我們無論是觀察或沒觀察到 Bunching,都極有可能只是統計偏誤。而 2000 年前稅收研究大多使用問卷調查資料(survey data),這樣的資料除了前述的小樣本問題外,還很容易出現測量誤差。1 因此在過去的稅收研究想分析類似問題時,總得仰賴一些很特殊的政策以取得良好的識別策略( identification strategy)。(這些計量方法上的介紹可以參閱白經濟的〈尋找平行世界的你:因果推論〉。) 在 2000 年後多國政府開始允許稅收研究使用全民等級的政府資料,而 Bunching Method 的發展就與這些巨量行政資料(administrative data)的普及密不可分。如果取得這樣的全民稅收資料,研究者就能把台灣的淨收入分佈圖畫出來,並用肉眼直接觀察到 Bunching 的存在與否,其中也不存在小樣本造成的偏誤,而且相對於問卷調查資料,行政資料的測量誤差就少得多了。最重要的是,Bunching 藉由直接處理全民母體資料來避免使用樣本資料時容易產生的內生性問題,以此取得因果推論。
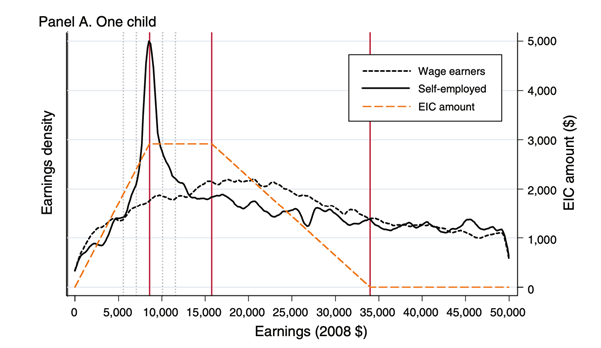
直觀上,如果我們在年收入 54 萬觀察到的 Bunching 越大,代表著原本收入略高於 54 萬的人的勞動供給彈性越大。藉由一些數學推導我們可以算出經濟模型中的勞動供給彈性,並依此給出政策建議,在此就不贅述模型的細節。讓我們試著站在政府的角度來想想看,勞動供給彈性究竟能給出什麼樣的政策幫助呢?我們假設政府的目標是要在總稅收超過某個固定額度的同時最大化個別民眾效用的總和,一言以蔽之就是要賺錢但不想擾民。2 在這樣的架構下,勞動供給彈性大的區間調高邊際稅率就不是那麼合適。原因在於,勞動供給彈性大的人很容易就能藉由降低自己的工作時數將自己的收入調整至較低稅率的區間,這樣的行為反應(behavioral response)導致調高邊際稅率的政策因為許多人離開該區間而收不到稅(賺不到錢),而人民調整收入其實也破壞了他們原先的勞動時數選擇,某種程度上一定降低了人們的效用(又擾民)。Bunching 正是上述所說的「人民將收入調整至低稅率」現象,而如果政府經由 Bunching Method 的實證研究率先知道了不同社經地位人民的勞動供給彈性,就能以此為基礎來進行福利分析並決定該在哪些收入區間調整邊際稅率。3 回到開啟了 Bunching Method 的 Saez (2010) ,他使用了美國的稅收資料來分析美國的勞動所得稅扣抵制(EITC)的影響(關於這個稅收制度的介紹可以閱讀白經濟的:〈關於基本收入的兩三事〉)。Saez 確實發現在第一個邊際稅率調整級距(第一條紅色垂直線)時有統計顯著的 Bunching 發生,而且自雇者比受雇者的 Bunching 大很多,以此推斷不同社經狀況、不同收入的人的勞動供給彈性有很大的差異。
Bunching 的後續研究
隨著行政資料的開放,Bunching Method 的應用也越來越廣,像是 Seibold (2019) 中就使用 Bunching Method 來分析德國法定退休年齡和退休金對退休決策的影響。但就如同使用任何一種計量方法時一樣,我們需要注意一些對於模型或人口分佈上的假設。我們以前述的模型來討論其中兩個假設以及它們所引發的後續研究:
- 模型假設 — 人可以無成本調整工時來效用極大化:在現實世界中,人們的行為和選擇會受到很多外在因素的干擾,舉例來說受雇者可能無法自由選擇工時、工作有慣性(inertia)因此不願意改變工時、也很有可能就只是沒有注意到稅收制度對收入的影響。其實現今的 Bunching Method 很多都應用在識別出這些外在因素干擾的效果。以 Saez (2010) 為例,受雇者和自雇者的勞動供給彈性差異很大,這很可能代表現實社會中這兩種人面臨的外在因素干擾非常不同,像是直覺上來看自雇者的確比較能自由調整工時。因此,Bunching 能幫助認定出經濟模型中外在因素干擾的大小,並在給予政策建議時就能將它們帶入福利分析之中。4
- 人口分佈假設 — 沒有基準點影響:在台灣的例子中,如果有某種因素導致人們聚集在年收入 54 萬(天馬行空的想像,可能公民課本有教,年收入 54 萬能達成理想的工作生活平衡),那麼 Bunching 很顯然無法反映真實的勞動供給彈性,這時 54 萬就是一個基準點(reference point)。在上述 Seibold 的論文中其實就探討了德國法定退休年齡的基準點效果。在德國的退休金制度的設計裡能讓許多不同年齡、狀況的人擁有相似的經濟誘因。舉例來說,輕度殘障的人和重度殘障的人在 60~65 歲之間每多工作一個月能拿到一樣的退休金加給。但在輕度殘障的人的退休金制度裡 63 歲卻有被標記為「正常退休年齡」,而重度殘障的人就沒有退休年齡的標記。藉由分析與上述例子類似(「相同」經濟誘因但不同「退休年齡」)的 Bunching 後他發現,經濟誘因無法解釋為何多數人選擇在法定退休年齡前一個月離職,因此推斷出非理性基準點效果的存在。
結語
這篇文章簡單的介紹了 Bunching Method 這個相對新穎的應用計量方法,其中省略許多初步的應用(如邊際和平均稅率改變的差異)以及有趣的延伸議題(避稅問題、社會福利政策等……),但也盡量保持它最重要的核心概念。若想進一步了解可以讀 Kleven 在 2016 年一篇極完整的 Bunching survey。 在這樣的介紹裡也能發現,任何計量方法的使用都脫離不了環境、制度及國家的影響,如 EITC、累進稅率和退休金制度對於如何詮釋 Bunching 至關重要。因此除了學好 Stata、R(對某些人,還有高微跟統計推論),深入了解現實世界的運作和良好的問題意識也是邁向好的實證經濟學徒或 data scientists 的一步。
參考資料
- Henrick Kleven, 2016, Bunching, Annual Review of Economics 8:1, 435–464
- Saez E. 2010. Do taxpayers bunch at kink points? Am. Econ. J. Econ. Policy 2:180–212
- Seibold, Arthur, Reference Points for Retirement Behavior: Evidence from German Pension Discontinuities (2019). CESifo Working Paper №7799.
- Hausman JA. 1983. Stochastic problems in the simulation of labor supply. In Behavioral Simulations in Tax Policy Analysis, ed. M Feldstein, pp. 47–69. Chicago, IL: Univ. Chicago Press
- Heckman J. 1983. Comment. In Behavioral Simulations in Tax Policy Analysis, ed. M Feldstein, pp. 70–82. Chicago, IL: Univ. Chicago Press
- Chetty R, Friedman JN, Saez E. 2013. Using differences in knowledge across neighborhoods to uncover the impacts of the EITC on earnings. Am. Econ. Rev. 103:2683–721